Optimising Butler for fun and profit
/ tags: adastralAs documented in my previous post, I found out with some questionable testing that butler is the best solution currently for Adastral’s versioning.
…That doesn’t mean we can’t make it better. One thing I already knew was that butler uses brotli compression (with the option for gzip instead). Brotli isn’t what came to my mind when I think of file compression, usually Zstandard does (see the arch repos) - I remember reading somewhere that this was a deliberate choice and that brotli just worked somewhere, but I can’t find any sources for that. With blazing fast decompression times, I thought changing to zstd compression would improve patching speed on clients, and maybe even lower patch generation times on servers!
Now to do this was easier than expected - They already had added zstd! Then removed it. Therefore, all I needed to do was just add it back in. This came with one main caveat: No resuming from bowls - i.e if the patchings interrupted, time to start all over.
This could be fixed (probably) in the future if it turns out to be needed though. Not important for now.
Butler also provides the option to specify the compression level (defaulting to 1), so I decided to test a few levels of Zstd, Gzip and brotli.
| butler diff sizes | brot, l1 | brot, l8 | gz, l9 | zstd, l10 |
|---|---|---|---|---|
| of-small | 32M | 25M | 30M | 26M |
| of-medium | 376M | 256M | 332M | 265M |
| of-large | 1.15G | 887M | 1.02G | 910M |
| butler diff times | brotli, l1 | brotli, l8 | gzip, l9 | zstd, l10 |
|---|---|---|---|---|
| of-small | 42s | 47s | 48s | 40s |
| of-medium | 7m51s | 8m13s | 9m1s | 7m30s |
| of-large | 8m35s | 10m20s | 10m51s | 8m16s |
As stated by one of my colleauges, diff time isn’t really a priority since our server time is less valuable than the end users, so if it reduces size at the cost of generation time going up modestly it’s worth it.
The data shows that zstd can drive down the size by a good amount without massively driving up the generation time, but that brotli generally outperforms it at L8 - I also did some preliminary testing with higher brotli levels and found out that the generation time goes up way too much to be worth it, for us anyway.
This is all quite important, however there’s one important thing that’s missing here - decompression speed!
| butler apply times | brotli | zstd |
|---|---|---|
| of-small | 2s | 2s |
| of-medium | 11s | 3s |
| of-large | 26s | 5s |
| tf2c-small | 37s | 34s |
| tf2c-large | 37s | 24s |
Now that’s a lot better - substantial improvements with zstd when it comes to those larger patch sizes, for OF especially. As a result, we decided to go with zstd with a higher level than tested (L14, as this provides something close to brotli l8 with the zstd decompression advantage).
That’s compression sorted - what’s next? Well butler has a very nice option to output a CPU profile for purposes such as this - so I did just that.
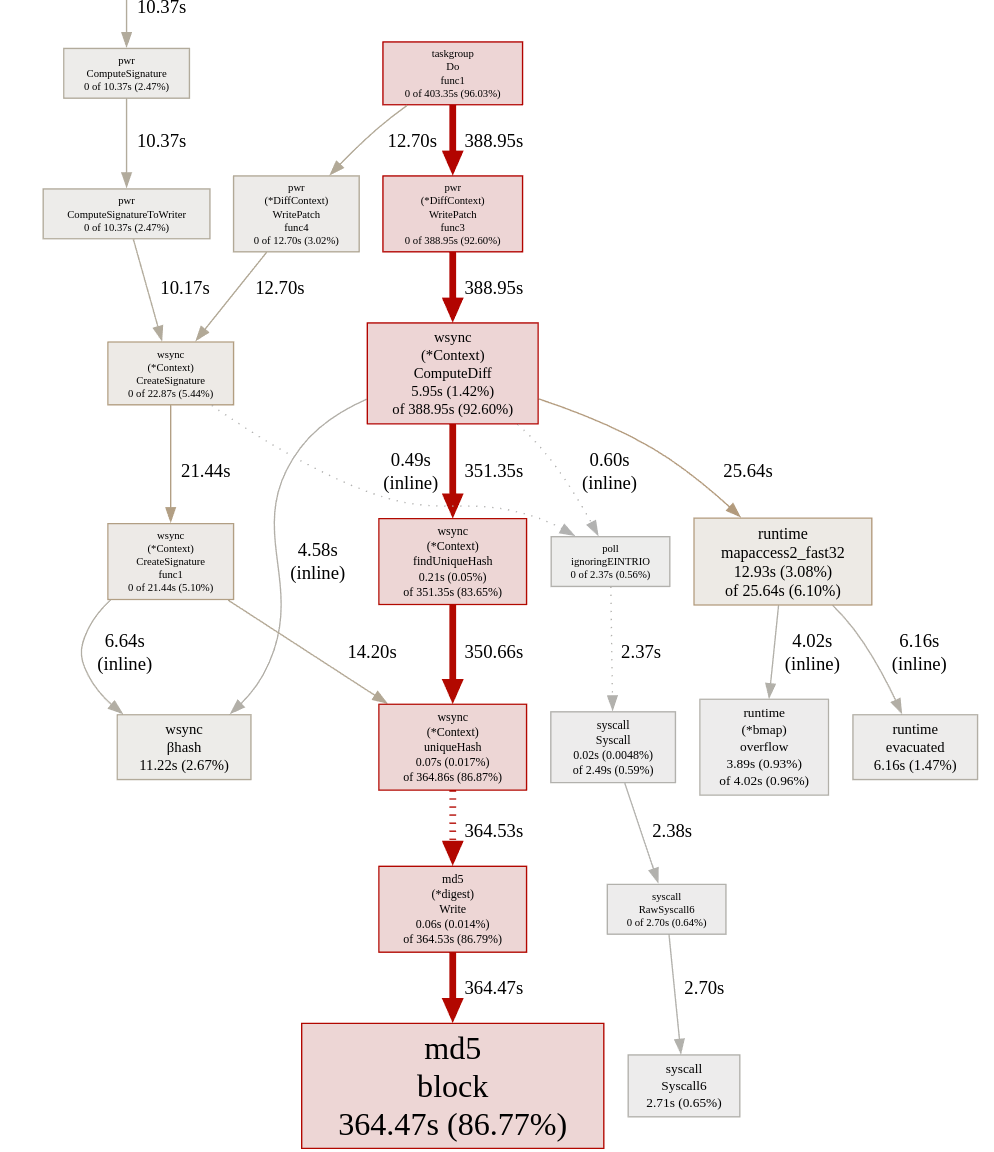
…That’s a good chunk of time spent doing nothing but working out MD5 hashes. There’s two ways of fixing this in theory:
- Computing less MD5 hashes
- Making the hashing faster
The latter was a lot easier since it’s effectively just “find something faster than MD5”. A quick cursory google search yielded something called highwayhash (ported to go). The throughput numbers can only be described as “stonking” (if they’re accurate):
BenchmarkHighwayHash 11986.98 MB/s
BenchmarkSHA256_AVX512 3552.74 MB/s
BenchmarkBlake2b 972.38 MB/s
BenchmarkSHA1 950.64 MB/s
BenchmarkMD5 684.18 MB/s
BenchmarkSHA512 562.04 MB/s
BenchmarkSHA256 383.07 MB/s
src:https://github.com/minio/highwayhash
I quickly patched wharf, the actual protocol behind butler, to use highwayhash for diffing instead of md5. The profile now looks like this:
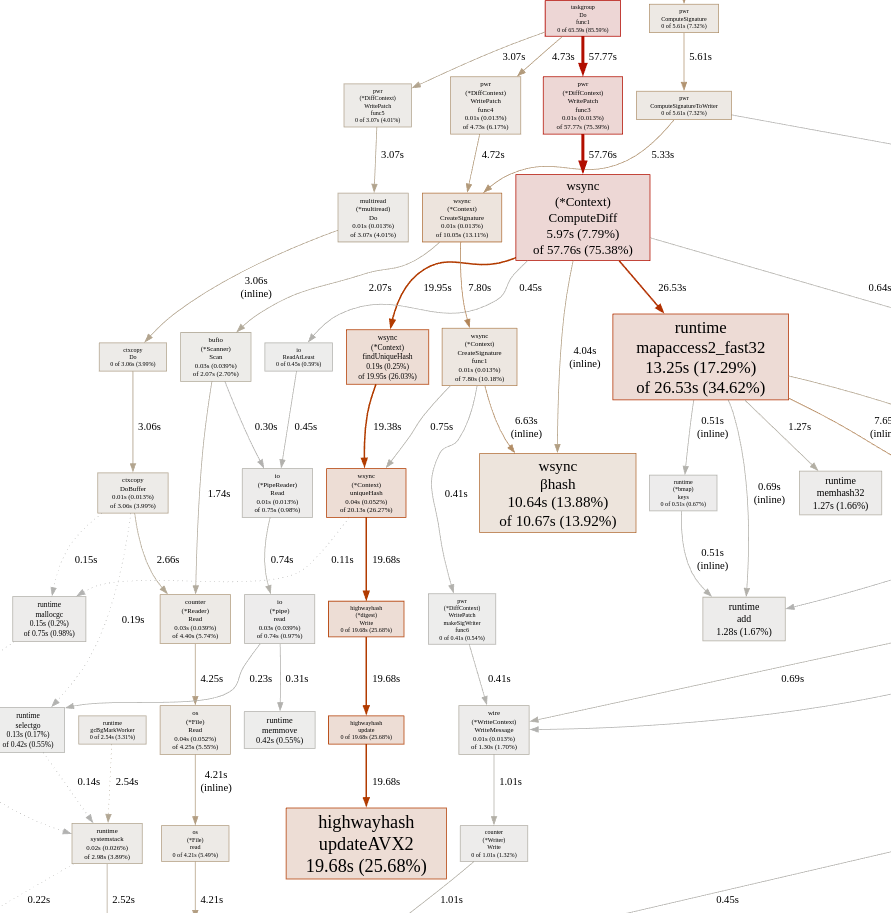
Much, much better. The speed improvements speak for themselves:
| butler diff times | md5 | highwayhash |
|---|---|---|
| of-small | 40s | 21s |
| of-medium | 7m30s | 1m57s |
| of-large | 8m16s | 2m51s |
| tf2c-small | 1m33s | 58s |
| tf2c-large | 4m0s | 2m49s |
This was surprisingly straightforward - didn’t require anything overly clever, and we’ve slashed patch generation time by over a half in some cases.
Is there more to be done? Probably, almost definitely. I’m not massively experienced in golang, Butler/Wharf is a sizeable codebase, and, most importantly, it’s not really the priority. Getting Adastral stable is. Premature optimisation and all that.
Until next time.
-kmt